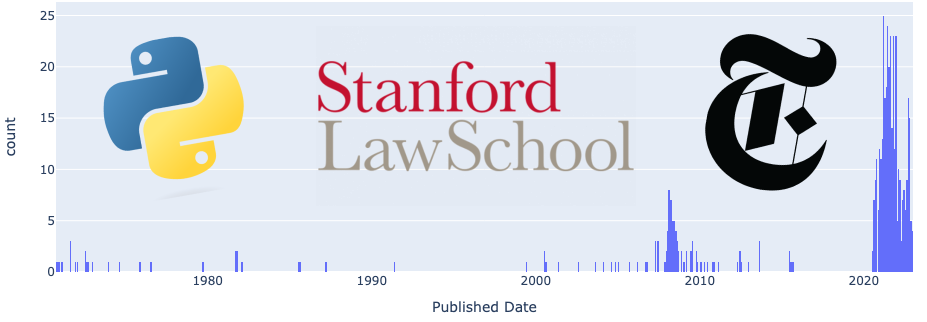
Research for Stanford Law on the prevalence of the search term ‘SPAC.’
Analyzing Financial Memes Using Data Science
Note from Author
This version of the NYT Spac analysis was modified to be formatted for this website. For a full, unabridged version, you can view it here: https://i-am-zach.github.io/NYT-SPAC-Analysis/
Stanford Law School: Analyzing Financial Memes Using Data Science
By Zach Lefkovitz (in coordination with Anonymous, Stanford Law School).
05/12/2023
https://github.com/i-am-zach/cmsc320-final-tutorial
Introduction
Special Purpose Acquisition Companies
Special Purpose Acquisition Companies (SPACs) are companies created solely for the purpose of raising capital through an initial public offering (IPO) with the intention of acquiring an existing private company and taking it public. SPACs are also known as “blank check” companies, as they have no operations or business activities at the time of their IPO. SPACs are highly criticized for over selling their companies /nyt-spac and being a method of enriching insiders.
An Opportunity is Presented

My good friend from back home, Zac, has an older brother (who chooses to remain anonymous) who attends Stanford Law School. This winter break, Zac reached out to me because his older was looking for a computer scientist to help assist him with a data science project for his research on SPACs. Not wanting to pass on an opportunity to make it into law review, I messaged my friend’s brother and started talking about the topic.
Professor Klausner
Professor Michael Klausner is a notable figure in the topic of special purpose acquisition companies at Stanford and I was introduced to his work. He notably published his article A Sober Look at SPACs in the Yale Journal on Regulation in 2020 that took a shot at SPACs for scamming their investors. A Sober Look at SPACs, has been cited by the SEC in proposing regulation to the industry and he is currently suing three SPACs in Delaware Court. Klausner is also a teacher for the Stanford Nancy and Charles Munger School of Business and Stanford Law School. His special research area is in Banking and Financial Institutions, Business & Corporate Law, and Capital Markets.
Research Purpose

In his research, we wanted to explore when and why SPACs became so popular. Through platforms like Twitter and Reddit’s r/WallStreetBets, SPACs became a financial meme. Using data science, Graham wanted to know exactly when SPACs started becoming popular. SPACs have been financial tools since the 90s but he hypothesizes there’s been a sharp increase in the use of SPACs in public knowledge starting in 2020.
Limitations
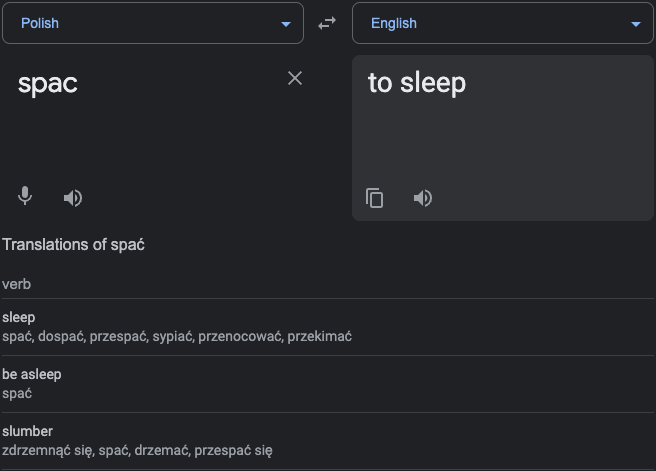
Since Twitter was a popular platform for the promoting and growing of SPACs as a financial meme, it would seem intuitive to scrape twitter content that contain the word “SPAC” for our data. However the word “spac” means “to sleep” in Polish so it would make analysis more complicated. While it would be possible to use an algorithm to determine the tweet was in English or Polish to filter the data, instead we decided to use New York Times articles as a measure of the prevalence of SPACs in public discourse.
Part 1: Data Collection
To collect the data, we are going to use the New York Times API. This API can be found by Googling “New York Times API” are going to the URL https://developer.nytimes.com/.
Creating an App
After creating a developer account with the New York Times, we need to create an app in order to obtain our API key. Under the accounts section on the top right, click on “apps” > Create New App. I created a new app called “NYT SPAC Analysis” and enabled the article search API.
Once the app is created, I copied my public and secret key and saved it to a .env file in my project’s root directory. My .env file follows this format:
NYT_API_KEY=<YOUR API KEY>
NYT_SECRET_KEY=<YOUR SECRET KEY>In the later parts of the project, I’ll load the environment variables from that .env file into my python script.
Exploring the Article Search API
The New York Times provides documentation for all their API endpoints. For the purpose of this project, we are going to use the article search API. The article search API allows NYT article look ups by keywords. The documentation can be found here: https://developer.nytimes.com/docs/articlesearch-product/1/overview.
From the NYT Article Search API documentation, here is an example API url:
https://api.nytimes.com/svc/search/v2/articlesearch.json?q=election&api-key=yourkey
Breaking down the url into its components:
https://api.nytimes.com/svc/search/v2/articlesearch.json: The base url for the article search API?q=election: Query for the keyword “election” in NYT articlesapi-key=yourkey: Dedicated keyword to provide your API key to authenticate the API
Some other useful query parameters useful for us:
sort= “newest” | “oldest” | “relevance”: Sort the API results by chronologically or by relevance. Sorting chronologically will be nice for graphing the data in time series.page= number: The API results are paginated with a max of 10 pages, meaning that to get all results that contain the SPAC keyword, we’ll have to exhaust all pages.
Formatting this API url to do a search for articles that include the word “SPAC” we get this URL
https://api.nytimes.com/svc/search/v2/articlesearch.json?q=SPAC&sort=oldest&page=1&api-key=yourkey
import requests
import os
from dotenv import load_dotenv
import json
import datetime as dt
import pandas as pd
import numpy as np
import plotly.express as px
import matplotlib.pyplot as plt
import seaborn as sns
from bs4 import BeautifulSoup
import plotly.io as pio
pio.renderers.default = "notebook_connected"
load_dotenv()Truedef article_search_by_keyword(keyword: str, api_key: str, page=1):
"""Query the NYT article search API by keyword and return the response as a JSON object.
@return None, Response: if the request fails
@return JSON object, Response: if the request succeeds
"""
url = "https://api.nytimes.com/svc/search/v2/articlesearch.json?q=%s&page=%d&sort=newest&api-key=%s" % (keyword, page, api_key)
res = requests.get(url)
if res.status_code != 200 or res.json()['response']['docs'] == []:
return None, res
return res.json(), resjson_res, _ = article_search_by_keyword("special purpose acquisition company", os.getenv("NYT_API_KEY"))
# json_res# json_res["response"]["docs"][0]Nice! Our query worked. We’re able to now make generalized HTTP requests to get article information from the New York Times!
for key in json_res['response']['docs'][0].keys():
print(key, type(json_res['response']['docs'][0][key]), sep=':\t')abstract <class 'str'>
web_url <class 'str'>
snippet <class 'str'>
lead_paragraph <class 'str'>
print_section <class 'str'>
print_page <class 'str'>
source <class 'str'>
multimedia <class 'list'>
headline <class 'dict'>
keywords <class 'list'>
pub_date <class 'str'>
document_type <class 'str'>
news_desk <class 'str'>
section_name <class 'str'>
subsection_name <class 'str'>
byline <class 'dict'>
type_of_material <class 'str'>
_id <class 'str'>
word_count <class 'int'>
uri <class 'str'>Since the New York Times API results are paginated, that makes we can only get 10 articles at a time. On each API call, we’re going to need to make a sequentially API call to next page, until we’ve exhausted all pages (and therefore received the complete data from the API query). We can not make all these requests at once other the NYT will rate limit us and prevent us from making requests. To work around then, after each request let’s set a timeout period to wait between requests.
NOTE: All the results of the API calls are saved in the data/nyt directory. This code is only left here to show how I collected the data and it’s not recommended running it because of how long it takes. I had the script run on my computer overnight to get all the API results.
import time
def get_all_articles_for_keyword(keyword: str, api_key: str, max_page=100, sleep_time_sec=6, start_page=1):
"""Query the NYT article search API by keyword and return all the responses as a list of JSON objects.
@return Response, Page: The response and page number of the last request when the request eventually fails
@return None: If the requests go past max_page
"""
os_friendly_keyword = keyword.replace(" ", "_")
# Make the /data/nyt directory if it doesn't exist
if not os.path.exists("data/nyt/%s" % os_friendly_keyword):
os.makedirs("data/nyt/%s" % os_friendly_keyword)
for page in range(start_page, max_page + 1):
json_res, res = article_search_by_keyword(keyword, api_key, page)
if json_res is None:
return res, page
with open("data/nyt/%s/%s_%d.json" % (os_friendly_keyword, os_friendly_keyword, page), "w") as f:
f.write(json.dumps(json_res))
print("%s: Finished page %d for keyword %s" % (dt.datetime.now(), page, keyword))
# Have to sleep for rate timing
time.sleep(sleep_time_sec)
# This while loop will run until an API rate limit is exceeded or until max_page is reached
start_page = 1
while True:
num_rate_limits = 0
error_res, page = get_all_articles_for_keyword("special purpose acquisition company", os.getenv("NYT_API_KEY"), start_page=start_page, sleep_time_sec=10, max_page=300)
if type(error_res) == bytes or error_res.status_code == 429:
num_rate_limits += 1
if num_rate_limits > 10:
break
start_page = page
print("Rate limit exceeded, sleeping for 1 minute")
time.sleep(60)
Part 2: Data Formatting
Combine the JSON Files to one dataframe for each keyword

NOTE: If you want to run this notebook without doing the tedious data collection, start here.
def json_to_df(data: dict):
"""Convert a JSON object from the NYT article search API to a pandas DataFrame.
@return DataFrame: The DataFrame representation of the JSON object
"""
return pd.DataFrame(data['response']['docs'])with open("data/nyt/special_purpose_acquisition_company/special_purpose_acquisition_company_1.json", "r") as f:
json_res = json.loads(f.read())
df = json_to_df(json_res)
df.head()| abstract | web_url | snippet | lead_paragraph | print_section | print_page | source | multimedia | headline | keywords | pub_date | document_type | news_desk | section_name | subsection_name | byline | type_of_material | _id | word_count | uri | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | The preliminary guidance applies to an alterna... | https://www.nytimes.com/2022/12/27/us/politics... | The preliminary guidance applies to an alterna... | WASHINGTON — The Treasury Department on Tuesda... | A | 16 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Treasury Department Outlines Rules f... | [{'name': 'subject', 'value': 'United States P... | 2022-12-27T22:58:06+0000 | article | Washington | U.S. | Politics | {'original': 'By Jim Tankersley', 'person': [{... | News | nyt://article/51e3a268-3b89-50c2-b801-3a750baa... | 600 | nyt://article/51e3a268-3b89-50c2-b801-3a750baa... |
| 1 | There were fewer mergers and public listings t... | https://www.nytimes.com/2022/12/23/business/wa... | There were fewer mergers and public listings t... | The luxury travel bookings will be more subdue... | B | 1 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'For Many Wall Street Bankers, This Y... | [{'name': 'subject', 'value': 'Banking and Fin... | 2022-12-23T08:00:10+0000 | article | Business | Business Day | NaN | {'original': 'By Maureen Farrell, Lauren Hirsc... | News | nyt://article/eaabf5ae-6d5d-5663-b8e2-2fa46f64... | 1321 | nyt://article/eaabf5ae-6d5d-5663-b8e2-2fa46f64... |
| 2 | An I.R.S. policy requires the agency audit pre... | https://www.nytimes.com/interactive/2022/12/21... | An I.R.S. policy requires the agency audit pre... | An I.R.S. policy requires the agency audit pre... | NaN | NaN | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Document: Report on the I.R.S. Manda... | [{'name': 'subject', 'value': 'Trump Tax Retur... | 2022-12-21T02:28:23+0000 | multimedia | U.S. | U.S. | Politics | {'original': None, 'person': [], 'organization... | Interactive Feature | nyt://interactive/e07fa384-7481-51b5-8d82-6a46... | 0 | nyt://interactive/e07fa384-7481-51b5-8d82-6a46... |
| 3 | Chamath Palihapitiya, once a relentless cheerl... | https://www.nytimes.com/2022/12/07/business/ch... | Chamath Palihapitiya, once a relentless cheerl... | Not long ago, Chamath Palihapitiya could be ca... | B | 1 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'The ‘SPAC King’ Is Over It', 'kicker... | [{'name': 'persons', 'value': 'Palihapitiya, C... | 2022-12-07T10:00:35+0000 | article | Business | Business Day | NaN | {'original': 'By Maureen Farrell', 'person': [... | News | nyt://article/26f371d9-968c-54e3-a955-cdbc8880... | 1748 | nyt://article/26f371d9-968c-54e3-a955-cdbc8880... |
| 4 | Yahoo’s chief executive sees the deal as a lon... | https://www.nytimes.com/2022/11/28/business/de... | Yahoo’s chief executive sees the deal as a lon... | Yahoo is deepening its push into digital adver... | B | 3 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Yahoo Takes Minority Stake in Ad Net... | [{'name': 'subject', 'value': 'Computers and t... | 2022-11-28T11:00:08+0000 | article | Business | Business Day | DealBook | {'original': 'By Lauren Hirsch and Benjamin Mu... | News | nyt://article/9cef1d89-b296-52aa-adc9-c75b69fc... | 679 | nyt://article/9cef1d89-b296-52aa-adc9-c75b69fc... |
# Combine all the JSON files in the SPAC and the special_purpose_acquisition_company directories into their respective DataFrame
spac_df = pd.DataFrame()
for file in os.listdir("data/nyt/spac"):
with open("data/nyt/spac/%s" % file, "r") as f:
json_res = json.loads(f.read())
spac_df = pd.concat([spac_df, json_to_df(json_res)])
spac_df.head()| abstract | web_url | snippet | lead_paragraph | print_section | print_page | source | multimedia | headline | keywords | pub_date | document_type | news_desk | section_name | byline | type_of_material | _id | word_count | uri | subsection_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | The company’s top executive resigned after the... | https://www.nytimes.com/2021/06/14/business/lo... | The company’s top executive resigned after the... | When Mary T. Barra, the chief executive of Gen... | A | 1 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Lordstown, Truck Maker That Can’t Af... | [{'name': 'organizations', 'value': 'Lordstown... | 2021-06-14T12:07:16+0000 | article | Business | Business Day | {'original': 'By Matthew Goldstein, Lauren Hir... | News | nyt://article/da4c9fa3-556e-5989-8b6f-9ec45506... | 1406 | nyt://article/da4c9fa3-556e-5989-8b6f-9ec45506... | NaN |
| 1 | How a powerful industry conquered the U.S. tax... | https://www.nytimes.com/2021/06/14/business/de... | How a powerful industry conquered the U.S. tax... | The $4.5 trillion buyout industry “has perfect... | NaN | NaN | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Private Equity’s Biggest Tax Tactics... | [{'name': 'subject', 'value': 'Federal Taxes (... | 2021-06-14T11:23:32+0000 | article | Business | Business Day | {'original': 'By Andrew Ross Sorkin, Jason Kar... | News | nyt://article/b3308881-073f-5092-bd37-77f2a034... | 1779 | nyt://article/b3308881-073f-5092-bd37-77f2a034... | DealBook |
| 2 | These complex takeover vehicles serve an impor... | https://www.nytimes.com/2021/06/12/business/de... | These complex takeover vehicles serve an impor... | The DealBook newsletter delves into a single t... | B | 3 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'In Defense of SPACs', 'kicker': 'dea... | [{'name': 'subject', 'value': 'Special Purpose... | 2021-06-12T12:00:04+0000 | article | Business | Business Day | {'original': 'By Steven Davidoff Solomon', 'pe... | News | nyt://article/91942d03-2916-523f-8906-9b578f19... | 997 | nyt://article/91942d03-2916-523f-8906-9b578f19... | DealBook |
| 3 | Inside Silicon Valley’s 10-year quest to make ... | https://www.nytimes.com/2021/06/12/technology/... | Inside Silicon Valley’s 10-year quest to make ... | To hear more audio stories from publications l... | BU | 1 | The New York Times | [] | {'main': 'What Is a Flying Car?', 'kicker': No... | [{'name': 'subject', 'value': 'Flying Cars', '... | 2021-06-12T09:00:30+0000 | article | SundayBusiness | Technology | {'original': 'By Cade Metz and Erin Griffith',... | News | nyt://article/d96f1acf-8d87-5298-969f-0af0b491... | 2340 | nyt://article/d96f1acf-8d87-5298-969f-0af0b491... | NaN |
| 4 | It’s been a blowout year for executive pay. | https://www.nytimes.com/2021/06/11/business/de... | It’s been a blowout year for executive pay. | Want to get the DealBook newsletter in your in... | NaN | NaN | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Behold the Highest-Paid C.E.O.s', 'k... | [{'name': 'subject', 'value': 'Executive Compe... | 2021-06-11T11:55:35+0000 | article | Business | Business Day | {'original': 'By Andrew Ross Sorkin, Jason Kar... | News | nyt://article/2fad74da-fca3-54e4-9e46-90851df7... | 1367 | nyt://article/2fad74da-fca3-54e4-9e46-90851df7... | DealBook |
verbose_spac_df = pd.DataFrame()
for file in os.listdir("data/nyt/special_purpose_acquisition_company"):
with open("data/nyt/special_purpose_acquisition_company/%s" % file, "r") as f:
json_res = json.loads(f.read())
verbose_spac_df = pd.concat([verbose_spac_df, json_to_df(json_res)])
verbose_spac_df.head()| abstract | web_url | snippet | lead_paragraph | print_section | print_page | source | multimedia | headline | keywords | pub_date | document_type | news_desk | section_name | byline | type_of_material | _id | word_count | uri | subsection_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Article on report released by Small Business A... | https://www.nytimes.com/2005/02/22/business/bu... | Article on report released by Small Business A... | ARE small businesses actually getting all the ... | G | 9 | The New York Times | [] | {'main': 'Case of the Missing Set-Aside', 'kic... | [{'name': 'organizations', 'value': 'Small Bus... | 2005-02-22T05:00:00+0000 | article | Small Business | Business Day | {'original': 'By Bernard Stamler', 'person': [... | News | nyt://article/bd7136af-4eab-51c7-83eb-85272fd1... | 1041 | nyt://article/bd7136af-4eab-51c7-83eb-85272fd1... | NaN |
| 1 | Article on win-win situation involving joint a... | https://www.nytimes.com/2005/02/20/nyregion/de... | Article on win-win situation involving joint a... | THE joint acquisition of more than a square mi... | WC | 14 | The New York Times | [] | {'main': 'In Somers, An Investment For Everyon... | [{'name': 'glocations', 'value': 'Somers (NY)'... | 2005-02-20T05:00:00+0000 | article | Westchester Weekly Desk | New York | {'original': 'By Elsa Brenner', 'person': [{'f... | News | nyt://article/a4955910-dd79-55ad-b18c-e18ddba7... | 1044 | nyt://article/a4955910-dd79-55ad-b18c-e18ddba7... | NaN |
| 2 | Profile of Jane Friedman, chief executive of H... | https://www.nytimes.com/2005/02/06/business/yo... | Profile of Jane Friedman, chief executive of H... | Correction Appended | 3 | 1 | The New York Times | [] | {'main': 'Michael Crichton? He's Just the Auth... | [{'name': 'organizations', 'value': 'NEWS CORP... | 2005-02-06T05:00:00+0000 | article | SundayBusiness | Books | {'original': 'By Edward Wyatt', 'person': [{'f... | News | nyt://article/fbdd8b9b-c467-53d2-9345-0919752e... | 2449 | nyt://article/fbdd8b9b-c467-53d2-9345-0919752e... | NaN |
| 3 | Earlier this month, Johnson & Johnson became o... | https://www.nytimes.com/2005/01/30/opinion/cor... | Earlier this month, Johnson & Johnson became o... | Earlier this month, Johnson & Johnson became o... | 4 | 16 | The New York Times | [] | {'main': 'Corporate Welfare Runs Amok', 'kicke... | [{'name': 'glocations', 'value': 'United State... | 2005-01-30T05:00:00+0000 | article | Editorial Desk | Opinion | {'original': None, 'person': [], 'organization... | Editorial | nyt://article/f60acba6-6b87-5e89-93d9-8c903413... | 681 | nyt://article/f60acba6-6b87-5e89-93d9-8c903413... | NaN |
| 4 | MICK JAGGER was there that night in 1996, watc... | https://www.nytimes.com/2004/12/26/business/dr... | MICK JAGGER was there that night in 1996, watc... | MICK JAGGER was there that night in 1996, watc... | 3 | 1 | The New York Times | [] | {'main': 'Dressing Down Tommy Hilfiger', 'kick... | [{'name': 'subject', 'value': 'APPAREL', 'rank... | 2004-12-26T05:00:00+0000 | article | SundayBusiness | Business Day | {'original': 'By Tracie Rozhon', 'person': [{'... | News | nyt://article/743bf758-5cf9-51c0-816c-cf5690ec... | 3432 | nyt://article/743bf758-5cf9-51c0-816c-cf5690ec... | NaN |
spac_df.shape(585, 20)verbose_spac_df.shape(2000, 20)# Check if there are duplicate articles in the spac_df and verbose_spac_df
spac_df['_id'].unique().shape, verbose_spac_df['_id'].unique().shape((585,), (2000,))Combine the DataFrames, removing duplicates
# Combine the two DataFrames and remove duplicates
# https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.combine_first.html
full_df = verbose_spac_df.set_index('_id').combine_first(spac_df.set_index('_id')).reset_index()
full_df.head()| _id | abstract | web_url | snippet | lead_paragraph | print_section | print_page | source | multimedia | headline | keywords | pub_date | document_type | news_desk | section_name | byline | type_of_material | word_count | uri | subsection_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | nyt://article/00333e27-a5aa-5453-a0fe-2489f23c... | (This article was reported by C. J. Chivers, E... | https://www.nytimes.com/2008/03/27/world/asia/... | (This article was reported by C. J. Chivers, E... | NaN | NaN | International Herald Tribune | [] | {'main': 'Supplier under scrutiny on aging arm... | [] | 2008-03-27T05:00:00+0000 | article | IHT News | World | {'original': 'By C. J. Chivers', 'person': [{'... | News | 4219 | nyt://article/00333e27-a5aa-5453-a0fe-2489f23c... | Asia Pacific | |
| 1 | nyt://article/003a5b2f-bfe7-5b1e-a049-8a4d372e... | The corporate practice of siphoning money fr... | https://www.nytimes.com/1983/09/25/business/pr... | The corporate practice of siphoning money from... | 3 | 1 | The New York Times | [] | {'main': 'Raiding Pension Plan', 'kicker': 'PR... | [{'name': 'subject', 'value': 'TERMS NOT AVAIL... | 1983-09-25T05:00:00+0000 | article | Financial Desk | Business Day | {'original': 'By Clyde H. Farnsworth', 'person... | Summary | 765 | nyt://article/003a5b2f-bfe7-5b1e-a049-8a4d372e... | NaN | |
| 2 | nyt://article/004f83e0-4289-5034-8eda-3f0d06c9... | Gary Gensler, the new S.E.C. chairman, wants t... | https://www.nytimes.com/2021/04/21/business/ec... | Gary Gensler, the new S.E.C. chairman, wants t... | Wall Street’s new watchdog, Gary Gensler, is c... | B | 1 | The New York Times | [{'rank': 0, 'subtype': 'xlarge', 'caption': N... | {'main': 'Manic Markets, Imploding Funds: Wall... | [{'name': 'persons', 'value': 'Gensler, Gary S... | 2021-04-21T14:05:15+0000 | article | Business | Business Day | {'original': 'By Matthew Goldstein', 'person':... | News | 1286 | nyt://article/004f83e0-4289-5034-8eda-3f0d06c9... | Economy |
| 3 | nyt://article/0056b3ce-dd83-5c26-9928-37d4f654... | Biog; illus | https://www.nytimes.com/1961/09/06/archives/co... | Biog; illus | BUSINESS FINANCIAL | 51 | The New York Times | [] | {'main': 'Co-Existence in the Retail War; Disc... | [{'name': 'organizations', 'value': 'GRAYSON-R... | 1961-09-06T05:00:00+0000 | article | None | Archives | {'original': 'By William M. Freeman', 'person'... | Archives | 0 | nyt://article/0056b3ce-dd83-5c26-9928-37d4f654... | NaN | |
| 4 | nyt://article/006fe0c5-ffc3-5ed1-9ec8-eed97e51... | Lehman message | https://www.nytimes.com/1938/01/06/archives/te... | Lehman message | NaN | 14 | The New York Times | [] | {'main': 'Text of Governor Lehman's Annual Mes... | [{'name': 'glocations', 'value': 'New York Sta... | 1938-01-06T05:00:00+0000 | article | None | Archives | {'original': 'Special to THE NEW YORK TIMES', ... | Archives | 0 | nyt://article/006fe0c5-ffc3-5ed1-9ec8-eed97e51... | NaN |
full_df.shape(2320, 20)# Save our DataFrame to a CSV file so we can just load it in the future
full_df.to_csv("data/nyt/nyt_spac.csv")# full_df = pd.read_csv("data/nyt/nyt_spac.csv")
# full_df.head()full_df.columnsIndex(['_id', 'abstract', 'web_url', 'snippet', 'lead_paragraph',
'print_section', 'print_page', 'source', 'multimedia', 'headline',
'keywords', 'pub_date', 'document_type', 'news_desk', 'section_name',
'byline', 'type_of_material', 'word_count', 'uri', 'subsection_name'],
dtype='object')full_df['pub_date'] = pd.to_datetime(full_df['pub_date']) # convert to datetime
full_df['abstract'] = full_df['abstract'].astype(str) # convert to string
full_df['lead_paragraph'] = full_df['lead_paragraph'].astype(str) # convert to stringPart 3: Data Exploration
Plotting The Occurrences of Articles over Time
# Get the 5 number summary of the publication dates
full_df['pub_date'].describe()/var/folders/x0/4wc1x1s934q1t58trc5dtw0h0000gp/T/ipykernel_22655/371600974.py:2: FutureWarning:
Treating datetime data as categorical rather than numeric in `.describe` is deprecated and will be removed in a future version of pandas. Specify `datetime_is_numeric=True` to silence this warning and adopt the future behavior now.
count 2320
unique 2212
top 2000-06-14 05:00:00+00:00
freq 3
first 1865-09-03 05:00:00+00:00
last 2023-01-20 21:02:30+00:00
Name: pub_date, dtype: object# Get the 5 number summary of the word counts
full_df['word_count'].describe()count 2320.000000
mean 1660.197845
std 4100.339873
min 0.000000
25% 0.000000
50% 852.000000
75% 1756.250000
max 102439.000000
Name: word_count, dtype: float64# Make a histogram of the publication dates, setting each month as a bin
px.histogram(full_df['pub_date'], nbins=full_df['pub_date'].dt.to_period('M').unique().shape[0])/var/folders/x0/4wc1x1s934q1t58trc5dtw0h0000gp/T/ipykernel_22655/2377877904.py:2: UserWarning:
Converting to PeriodArray/Index representation will drop timezone information.// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div>Looking at this graph, we see the majority of the articles start around 1930. Trim the data only include entries with publication dates >= 1930
full_df = full_df[full_df['pub_date'] > dt.datetime(1930, 1, 1).astimezone(tz=dt.timezone.utc)]g = px.histogram(full_df, x='pub_date', nbins=full_df['pub_date'].dt.to_period('M').unique().shape[0])
g.update_layout(
title = "Number of NYT Articles with the keyword SPAC or Special Purpose Acquisition Company by Month",
xaxis_title = "Month",
yaxis_title = "Number of Articles"
)
g.update_xaxes(
tickangle = 45,
tickformat = '%b %Y'
)/var/folders/x0/4wc1x1s934q1t58trc5dtw0h0000gp/T/ipykernel_22655/3243197738.py:1: UserWarning:
Converting to PeriodArray/Index representation will drop timezone information.// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div>As our hypothesis stated, there is a spike in NYT articles containing the keyword “SPAC” or “Special Purpose Acquisition Company” in 2020/2021.
Relationship Between Time and Word Count
# Do the word counts and publication dates correlate?
px.scatter(full_df, x='pub_date', y='word_count')// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div># Use a log scale for the y axis
g = px.scatter(x=full_df['pub_date'], y=np.log(full_df['word_count']))
g.update_layout(
title = "Log of Word Count vs Publication Date",
xaxis_title = "Publication Date",
yaxis_title = "Log of Word Count"
)/Users/work/opt/anaconda3/envs/python311/lib/python3.11/site-packages/pandas/core/arraylike.py:402: RuntimeWarning:
divide by zero encountered in log// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div>From this scatter plot, we can see their does not seem to be an apparent relationship between the article’s publication date and the word count.
Exploring Section Names of Articles
# See the most common sections the articles appear in
px.bar(full_df.value_counts('section_name')[full_df.value_counts('section_name') >= 10])// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div>Part 4: Data Analysis
Machine Learning (Topic Modeling)
Topic modeling is a type of statistical modeling for discovering the abstract topics that occur in a collection of documents. Essentially, it is a method for finding a group of words (i.e., a topic) from a collection of documents that best represents the information in the collection. It’s a form of text mining - a way to identify patterns in a large collection of text data, which we often refer to as a “corpus”.
Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) is an example of a topic model and is used to classify text in a document to a particular topic. It builds a topic per document model and words per topic model, modeled as Dirichlet distributions.
The LDA model discovers the different topics that the documents represent and how much of each topic is present in a document. In essence, it assumes that each document in a corpus is a combination of a finite number of topics, and each word in the document can be attributed to one of the document’s topics.
Why Use LDA for Analyzing the New York Times Articles on Special Purpose Acquisition Companies (SPACs)?
As we have a large number of articles from the New York Times relating to SPACs, it becomes nearly impossible to read through every article and understand the key themes or topics manually. That’s where the LDA model becomes particularly useful.
Using LDA for this task helps us automatically discover the main topics discussed in these articles, providing a high-level overview of the common themes. By applying the LDA model, we can find out which topics were most prevalent over time, helping us understand how the discussion around SPACs has evolved.
It can also highlight the context in which SPACs are being discussed, such as in relation to financial regulations, market trends, or specific industries. This information can be crucial in providing a more structured and deep understanding of the news corpus.
In conclusion, LDA is a powerful tool for analyzing large collections of text data, uncovering hidden thematic structures, and helping in the understanding of large-scale trends and patterns. By using LDA in conjunction with Python’s Scikit-Learn library, we can effectively analyze and interpret our corpus of New York Times articles.
Resources
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.feature_extraction.text import ENGLISH_STOP_WORDS
# Combine the abstract and lead_paragraph columns into one column
full_df['text'] = full_df['abstract'] + '\n' + full_df['lead_paragraph']
# Want to exclude "New York City" from the LDA model along with the default english words
custom_stop_words = list(ENGLISH_STOP_WORDS)
custom_stop_words.extend(['new', 'york', 'city'])
# Transform the 'abstract' column into a document-term matrix
vectorizer = CountVectorizer(max_df=0.95, min_df=2, stop_words=custom_stop_words)
dtm = vectorizer.fit_transform(full_df['text'])
dtm.shape(2290, 10322)# Train LDA model
# Note: You might want to tune the number of topics (n_components parameter)
lda = LatentDirichletAllocation(n_components=10, random_state=42)
lda.fit(dtm)LatentDirichletAllocation(random_state=42)In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook.
On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
LatentDirichletAllocation(random_state=42)
topic_results = lda.transform(dtm)top_words = 5 # Number of top words in each topic
feature_names = vectorizer.get_feature_names_out()
# For each document, get the top words in each of its top topics
top_words_for_each_doc = []
top_topic_for_each_doc = []
top_topic_prob_for_each_doc = []
for prob_dist in topic_results:
# Get the probability of the top topic for this document
top_topic_prob = np.sort(prob_dist)[-1]
top_topic_prob_for_each_doc.append(top_topic_prob)
# Get the top topic for this document
top_topic = np.argsort(prob_dist)[-1]
top_topic_for_each_doc.append(top_topic)
# Get the top words for this topic
top_words_for_topic = np.argsort(lda.components_[top_topic])[::-1][:top_words]
top_words_for_each_doc.append([feature_names[i] for i in top_words_for_topic])
full_df['main_topic_index'] = top_topic_for_each_doc
full_df['main_topic_prob'] = top_topic_prob_for_each_doc
full_df['main_topic'] = top_words_for_each_doc
full_df['main_topic_str'] = full_df['main_topic'].apply(lambda x: ', '.join(x))# Some of the entries have empty of not useful abstracts and lead paragraphs
# Remove those entries
clean_df = full_df[full_df['lead_paragraph'].notna()] # Remove rows where 'lead_paragraph' is NaN
clean_df = clean_df[clean_df['lead_paragraph'].str.strip() != ''] # Remove rows where 'lead_paragraph' is whitespace or empty string
clean_df = clean_df[clean_df['abstract'].str.split().str.len() >= 3] # Keep rows where 'abstract' has at least three words
clean_df.shape
(1710, 25)# Print a random sample of 5 articles and their main topic
for abstract, lead_paragraph, main_topic_prob, main_topic in clean_df[['abstract', 'lead_paragraph', 'main_topic_prob', 'main_topic']].sample(n=5).values:
print("Abstract: %s" % abstract)
print("Lead Paragraph: %s" % lead_paragraph)
print("Main Topics: %s" % main_topic)
print("Main Topic Probability: %s" % main_topic_prob)
print()Abstract: LEAD: Robert Maxwell comes lum-bering toward the waiting helicopter.
Lead Paragraph: Robert Maxwell comes lum-bering toward the waiting helicopter.
Main Topics: ['company', 'acquisition', 'deal', 'companies', 'said']
Main Topic Probability: 0.5209040459869437
Abstract: "It will probably be the most interesting thing we have ever done," says Jules Kroll. The world's most famous gumshoe is matter-of-fact about his company's latest major international assignment: the Republic of Russia has hired it to locate the money -- an estimated $6 billion to $8 billion in 1991 alone -- believed to have been spirited out of the country by the directors of state enterprises when they realized that privatization was inevitable. The Russian Government wants Kroll to get the money back.
Lead Paragraph: "It will probably be the most interesting thing we have ever done," says Jules Kroll.
Main Topics: ['com', 'designer', 'style', 'slide', 'times']
Main Topic Probability: 0.8852844100115668
Abstract: Nature Conservancy acquires 1,300-acre tract of beaches, dunes and rare wetlands on LI south fork near Hither Hills State Pk for $8.5-million; plans to sell tract to NYS at no profit; property was purchased from Hanson Properties Inc and Atlantic Processing Co; orgn spokesman says group borrowed money at special low-interest rates from Citibank; rare flora and fauna indigenous to tract noted; area map (M)
Lead Paragraph: PORT JEFFERSON L.I., Dec. 29—New York State will soon acquire a 1,300‐acre area of beaches, dunes and rare wetlands on Long Island's South Fork.
Main Topics: ['text', 'wall', 'street', 'says', 'state']
Main Topic Probability: 0.9849968701836254
Abstract: The Treasury secretary said that borrowing costs remained high despite government efforts.
Lead Paragraph: Despite huge government efforts to restore lending to normal, Treasury Secretary Timothy F. Geithner said Tuesday that borrowing costs remained high and credit was still not flowing normally.
Main Topics: ['bank', 'president', 'trump', 'media', 'social']
Main Topic Probability: 0.9709643287303419
Abstract: Following is the full text of the principal findings of the special committee investigating financial improprieties among Hollinger International Inc. executives. The report was filed today with the Securities and Exchange Commission.
Lead Paragraph: Following is the full text of the principal findings of the special committee investigating financial improprieties among Hollinger International Inc. executives. The report was filed today with the Securities and Exchange Commission.
Main Topics: ['company', 'acquisition', 'deal', 'companies', 'said']
Main Topic Probability: 0.49392439808855293# Find the most common topics and their average probabilities
count_topic_df = clean_df \
.groupby('main_topic_str') \
.count()[['_id']] \
.reset_index() \
.rename(columns={'_id': 'Count', 'main_topic_str': 'Topic'}) \
.sort_values('Count', ascending=False)
avg_topic_prob_df = clean_df \
.groupby('main_topic_str') \
.mean(numeric_only=True)[['main_topic_prob']] \
.reset_index() \
.rename(columns={'main_topic_prob': 'Avg. Probability', 'main_topic_str': 'Topic'}) \
count_topic_df = count_topic_df.merge(avg_topic_prob_df, on='Topic')
count_topic_df| Topic | Count | Avg. Probability | |
|---|---|---|---|
| 0 | company, acquisition, deal, companies, said | 467 | 0.705027 |
| 1 | bank, president, trump, media, social | 199 | 0.726280 |
| 2 | public, year, million, company, saratoga | 193 | 0.758899 |
| 3 | percent, company, said, shares, stake | 173 | 0.797069 |
| 4 | text, wall, street, says, state | 143 | 0.758902 |
| 5 | company, times, government, american, cbs | 129 | 0.773991 |
| 6 | united, states, president, washington, today | 125 | 0.740687 |
| 7 | company, said, steel, electric, motors | 118 | 0.754455 |
| 8 | com, designer, style, slide, times | 104 | 0.746683 |
| 9 | street, 212, tickets, 30, tomorrow | 59 | 0.575200 |
As the above table shows, extracted from the article abstract and leading paragraphs, the topic all the most popular topics are related to business terms like “company,” “money,” and “stock.” The highest ranking topic with 467 articles that best fit that topic has the words “company, acquisition, deal, companies, said.” These words strongly match the phrase special purpose acquisition company, giving good confidence to the quality of our data.
NLP (Sentiment Analysis)
What is Natural Language Processing?
Natural Language Processing (NLP) is a subfield of artificial intelligence and computational linguistics that focuses on the interaction between computers and humans through natural language. The goal of NLP is to enable computers to understand, interpret, and generate human language in a valuable way.
NLP involves several tasks, including but not limited to:
- Text Analysis: Understanding the structure of the language, including grammar and syntax.
- Semantic Analysis: Understanding the meaning of the text.
- Sentiment Analysis: Determining the sentiment or emotion expressed in the text.
- Text Generation: Creating meaningful text based on certain inputs or requirements.
NLP in Our Project
It’s one thing to have a lot of articles published on a topic. It’s another thing to know if there articles are positive or negative. While some say that all publicity is good publicity, we are interested in finding out more about public awareness and public opinion on SPACs. Whether these articles have positive or negative sentiment to them matters for this case.
One of the columns of our NYT articles dataframe is web_url which contains the link to the published article on the New York Times website. In theory, we could request the HTML content of all these web pages, scrape the web page so we are only getting the text content, and then running NLP on the text for each article. In practice, this proves to be quite difficult.
- Our data frame has roughly 2,500 rows, meaning we’d have to scrape 2,500 websites. Making that many requests to the New York Times would likely cause a rate limit.
- The New York Times puts all its articles behind a paywall and does not load the article’s content unless its reader logs in.
- Not all New York Times articles are guaranteed to put their article content in the same HTML tag
Resources
test_web_url = full_df.sort_values('pub_date', ascending=False).iloc[0]['web_url']
test_web_url'https://www.nytimes.com/2023/01/20/business/media/vice-puts-itself-up-for-sale.html'res = requests.get(test_web_url)
res.contentb'<html><head><title>nytimes.com</title><style>#cmsg{animation: A 1.5s;}@keyframes A{0%{opacity:0;}99%{opacity:0;}100%{opacity:1;}}</style></head><body style="margin:0"><p id="cmsg">Please enable JS and disable any ad blocker</p><script data-cfasync="false">var dd={\'rt\':\'c\',\'cid\':\'AHrlqAAAAAMAl5sIanRzcdYAgQJZKA==\',\'hsh\':\'499AE34129FA4E4FABC31582C3075D\',\'t\':\'bv\',\'s\':17439,\'e\':\'640143223d3583113180365187720914bb64b245f82387444835d77e1b96a39f\',\'host\':\'geo.captcha-delivery.com\'}</script><script data-cfasync="false" src="https://ct.captcha-delivery.com/c.js"></script></body></html>\n'soup = BeautifulSoup(res.content, 'html.parser')
soup.find_all(string="Please enable JS and disable any ad blocker")['Please enable JS and disable any ad blocker']# The new york times publishes text content in the <article> tag
soup.find("article") is NoneTrueSince we can’t easily make HTTP requests to scrape NYT article text content, we should look to our DataFrame for columns which we can do NLP on. We’ll use the text column that we created for the Topic Modeling which is the combination of the abstract and lead paragraph.
import nltk
nltk.download('vader_lexicon')[nltk_data] Downloading package vader_lexicon to
[nltk_data] /Users/work/nltk_data...
[nltk_data] Package vader_lexicon is already up-to-date!
Truefrom nltk.sentiment.vader import SentimentIntensityAnalyzer
sid = SentimentIntensityAnalyzer()
def get_sentiment(text):
# Get the sentiment scores
sentiment_scores = sid.polarity_scores(text)
# Return the compound score
return sentiment_scores['compound']
clean_df['sentiment'] = full_df['text'].apply(get_sentiment)import plotly.graph_objects as go
fig = px.histogram(
clean_df,
x='sentiment',
color_discrete_sequence=['lightblue'],
opacity=0.8,
title='Sentiment Score Distribution of SPAC NYT Articles',
labels={'sentiment':'Sentiment Score', 'count': 'Proportion'},
)
fig.update_layout(bargap=0.05)
fig.show()// Listen for the removal of the full notebook cells var notebookContainer = gd.closest(‘#notebook-container’); if (notebookContainer) {{ x.observe(notebookContainer, {childList: true}); }}
// Listen for the clearing of the current output cell var outputEl = gd.closest(‘.output’); if (outputEl) {{ x.observe(outputEl, {childList: true}); }}
}) }; }); </script> </div>As we can see from the histogram of sentiment scores on our cleaned dataset, the distribution of the sentiment scores appears to be bimodal with peaks at 0 and 0.9. From the information gathered about the articles’ abstract and leading paragraph (note this is a limitation on the accuracy of our sentiment analysis) a large amount of sentiments are either neutral or very positive. This result is unexpected as I’d imagine that the sentiment on articles written about SPACs would be closer to neutral or negative.
There are a few possible explanations for this.
- The training data of the vader lexicon NLP model trained on data that looks significantly different (and more negative) from from the NYT article data we are feeding it.
- Related, the NYT write their articles in such a way that sentiment of their abstracts and leading paragraphs are either in a neutral or positive tone. This would explain the peak around 0.0 as most journalist try to write in an unbiased tone unless they are writing op-eds.
- The NYT writers hold favorable views of SPACs and are writing positive articles on them.
Of the explanations, I believe that explanation #1 is most likely. To better tune the model, we could train it on other abstracts and leading paragraph from a random, representative group of NYT articles. This however is outside of the scope of the project but would be interesting to explore.
Part 5: Conclusion and Insight
Through this project, we learned:
- What a SPAC (special purpose acquisition company) is and a notable researcher in the field.
- How to use the NYT API
- New York Times articles with the keyword “special purpose acquisition company” or “SPAC” saw a huge spike in 2020/2021
- What a LDA (Latent Dirichlet Allocation) is and how we can classify documents using it
- The most common topics for NYT articles with the keyword SPAC are all heavily business and finace related.
- The high amount positive sentiment in New York Times articles with the keyword SPAC